During the master we are given a choice of projects to work on within one semester. This was one of them in a team of 6 students. The following text is taken from our GitHub repository:
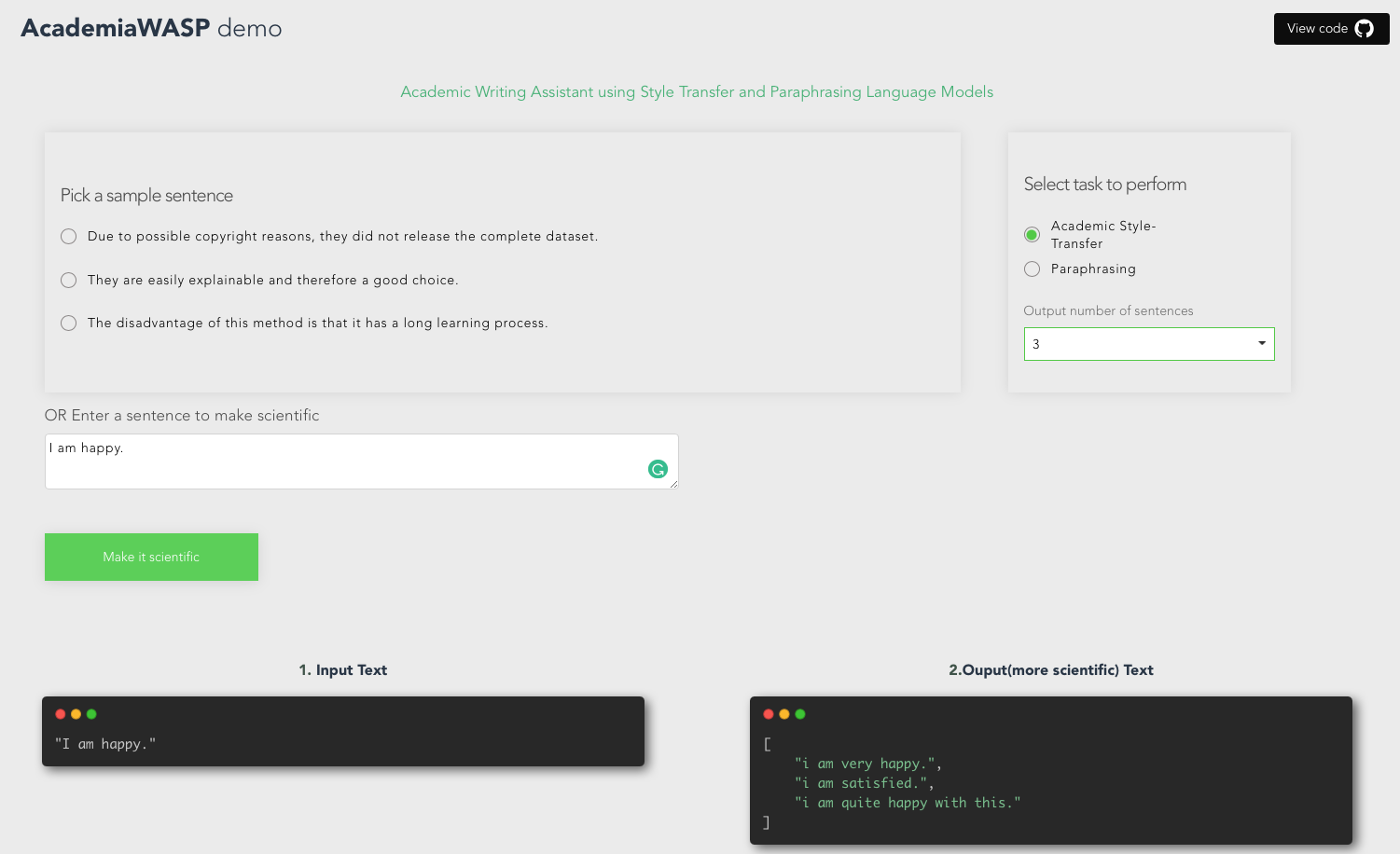
This Master Research Project dealt with the creation and evaluation of a natural language processing tool to improve the scientific style of sentences without changing their semantic content. In a first step we have fine-tuned GPT-2 and T5 pretrained models using a previously proven pseudo-parallel dataset of original and paraphrased sentences to generate pseudo parallel data by paraphrasing a heavily filtered set of scientific sentences. In this context we developed a new evaluation metric for diverse paraphrase generation. In a second step we fine-tuned GPT-2 and T5 models for style-transfer using filtered and cleaned sentences from the previously created pseudo-parallel data. We then evaluated the performance of these models based on classifiers that we developed in the scope of our research questions.
Our research goal was to find techniques for evaluating the performance of said scientific style transfer models. Because the scientificity of a sentence is manifold, we applied a combination of measures and models to validate the success of style transfer and the success of semantic preservation. For the evaluation of style transfer we used a RoBERTa classifier trained on sentences with TF-IDF masked tokens as well as an SVM model using handcrafted features. We found that this TF-IDF masking is necessary to ensure such classifiers do operate on style and not on content of the corpora they are trained on. For the semantic preservation we applied Moverscore and doing so critically discussed the applicability and the shortcomings of this novel metric. Moreover, we trained a classifier on the CoLA dataset to assess fluency of the output of our model. We also reviewed the performance of this classifier more critically than related work has done.
Finally, we find as a bottom line to our report, that our defined target group of users for whom this scientific style transfer model will be useful are students, as evaluation shows the most success in style transfer on student reports. However, our analysis also shows that the developed model is not yet sufficiently robust for reliable performance, as some sentences loose scientificity during transfer (especially already scientific ones) and as human evaluation did not achieve the desired results.
After submitting the university project and giving the final presentation, we worked hard to submit our work to the EMNLP 2021 Demo Track. This included writing a paper (in review), deploying our models to the Google Cloud Platform (let us know if you want to sponsor us) and creating a website in vue.js, which is accessible at http://writingassistant.ml.
The code is on Github: https://github.com/AcademiaAssistant/AcademiaWASP-LM